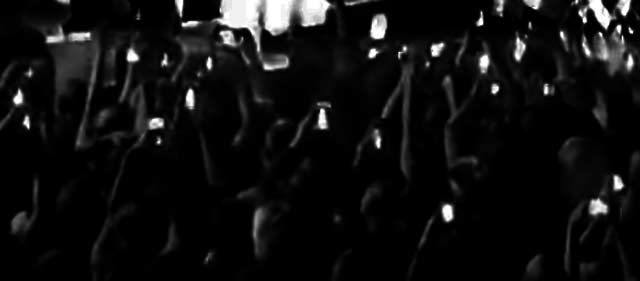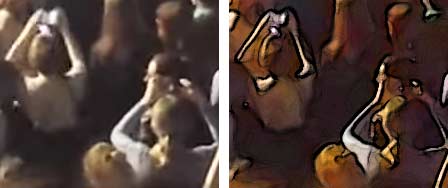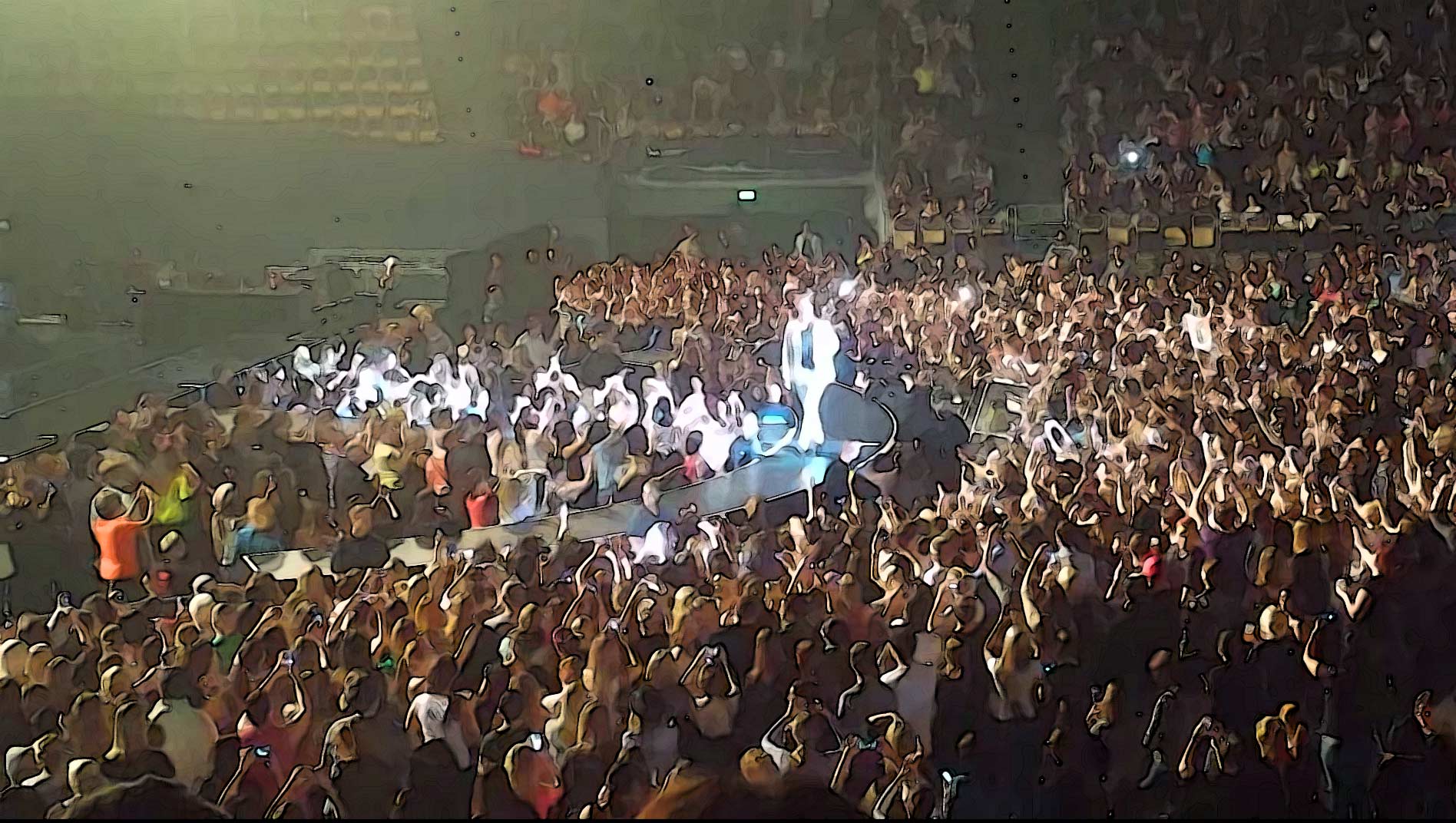artikel in der studio-fachzeitschrift production partner, 2004
2004 flog ich nach wien, weil dort ein orchestrales großprojekt startete: die digitalisierung von orchestern, einzelinstrumenten, chören, orgeln und sogar räumen in bisher nie dagewesener qualität und variabilität. das endprodukt ist eine software-suite für PC und mac, die den computer in ein, ja, orchester verwandelt, das man über die MIDI-tastatur spielt. daraus entstand ein langer artikel im Production Partner (→ pdf mit dem artikel) und ein halbstundenfeature im deutschlandfunk: → der digitale konzertsaal.
der besuch war so inspirierend, dass ich ein oder zwei jahre später nochmal dahinflog und das team von musikern und toningenieuren dabei beobachtete, wie sie alte konzertsäle akustisch ausmaßen. sehr aufwändig, aber wie man heute sieht (und hört) einzigartig am PC einsetzbar. man kann die virtuellen instrumente an beliebige stelle im schubertsaal positionieren; wenn man sie dreht, klingen sie völlig anders usw. in der musikinformatik läuft dieses thema unter faltungshall oder convolution reverb. wieder eine wissenschaftssendung im deutschlandfunk: → digitale raumklangausbeute (2005).
jedenfalls habe ich jetzt einen artikel über die vienna symphonic library in die englische wikipedia gesetzt. → hier ist er. in der → deutschen gibt es ihn schon länger. in der englischen gab es früher probleme damit, wie die löschhistorie zeigt, u. a. hier, 2008:
Delete as blatant hoaxA photo on the article has a caption stating that it is Joel Kass conducting with the Vienna Symphonic Orchestra. A music sample states that it is from a recording by the London Philharmonic Orchestra. Another music sample states that it is from a recording from the New York Philharmonic. Yet there’s nothing on the internet that I can find about these orchestra performing any music composed or conducted by Joel Kass. I note that none of the photos depict anyone clearly. I also note that the music samples all exceed the 30 seconds limit of fair use and that there is a lack of info regarding where the recording is from. Article also makes many other outlandish claim about collaborating with the likes of Mariah Carey, Toni Braxton and Dr. Dre. I have the New Grove Dictionary of Music with me and there is no Joel Kass in there. If this article is legitimate, this guy should be in there. Closing admin, please delete all the related photos and music samples as well. —Bardin (talk) 04:33, 11 July 2008 (UTC)
aber das ist eine andere geschichte (die ich nicht kenne).
mein neuester trailer für den deutschlandfunk, gestern erst fertiggestellt, lief heute zum ersten mal in forschung aktuell: „afrikas vergessene krankheiten“. die reihe startet im august, wir bewerben sie in loser folge aber jetzt schon:
trailer für die forschung-aktuell-reihe „afrikas vergessene krankheiten“
der trailer basiert auf einer afrikanisch anmutenden musik, die ich weitgehend mit native instruments‘maschine eingespielt habe, also mit den fingern. weil die congas tendenziell ein positives lebensgefühl vermitteln, es in der serie aber um schwere krankheiten geht, fügte ich stellenweise auftauchende streicher in moll ein. (halion/steinberg). einige o-töne aus franziska badenschiers beiträgen und features (sie ist die autorin der reihe) runden den soundtrack ab. sie müssen nicht beim ersten mal verständlich sein; es soll eine anmutung entstehen, mehr nicht. der trailer wird mehrmals laufen, und viele hörer, die forschung aktuell regelmäßig hören, dürfen noch was entdecken. die kinderstimmen, die ich in einen großen hall geschickt habe, stammen aus einem von epedemien heimgesuchten dorf.
die sprecherstimmen müssen natürlich sofort verständlich sein. die aufnahmen dazu entstanden letzte woche mit drei ensemblesprechern des deutschlandfunks: bettina scholmann, martin schaller und christoph wittelsbürger. ihre stimmen sind von den nachrichten im deutschlandfunk wohlbekannt, ich habe aber versucht, sie so zu „führen“, dass sie ein wenig anders klingen. mit bettina und christoph habe ich schon oft zusammengearbeitet; martins stark zurückgenommene sprechweise (er sagt in diesem trailer zum beispiel „armut macht krank“ und „tropische hitze“) war mir neu – sie klingt fantastisch.
die mischung des halbminüters war dann nicht mehr sehr komplex. damit bettina den titel der serie, eben „afrikas vergessene krankheiten“, abgehoben vom rest sprechen konnte, unterbrach ich den rhythmus an der stelle; er setzt erst wieder ein, wenn sie den titel gesprochen hat. am ende kommt christophs warmes timbre mit den sendedaten.
das bild oben zeigt smartphones, mit eingeschaltetem kamera-modus, etwa 30 an der zahl. die originalaufnahme (unten) habe ich einem video entnommen, das aus der gefühlten 5. reihe heraus aufgenommen wurde, bei einem großkonzert mit lana del rey in berlin diese woche.
wenn wir aus der 5. reihe etwa 30 leuchtende smartphones sehen, wären es aus reihe 20 schon 120 bildschirme. fast alle smartphones sind weiß, dem aufbau nach mehrheitlich iPhones, gefolgt von samsung galaxys. der weißabgleich funktioniert bei fast allen kameras gut. nur ein iPhone (drittes von rechts, unten) zeigt mehr blau als lila.
gefühlt würde ich sagen: fast alle halten ihr smartphone hoch; weil aber die anderen, die es nicht tun, unauffällig sind, müsste man das vielleicht auf 70% herunterkorrigieren. etwa zwei drittel der foto/filmer halten das gerät hochkant. selbst wenn einige nur fotografieren und nicht filmen, kann man also davon ausgehen, dass viele filme im hochkantformat entstanden, also völlig untauglich für querformatige bildschirme.
etwas über die hälfte der „user“ halten ihr gerät (mit einer art affengriff von oben) mit zwei händen. offenbar ist es zu riskant, das gerät fallen zu lassen.
standbild aus einem youtube-video eines lana del rey konzerts im juni 2014 in berlin
nehmen wir ein noch größeres konzert – backstreet boys, märz 2014, olympiahalle münchen – für eine kleine analyse:
oben ein ausschnitt aus einem youtube-mitschnitt, mit einem smartphone aus den oberen rängen links gefilmt. im dunklen meer des publikums sind die auf die bühne gerichteten smartphones als helle punkte zu sehen, allein in diesem ausschnitt einige hundert. unten die vergrößerung eines details aus dem bild: sie allein zeigt schon 30 smartphones:
detail aus dem foto oben: allein in diesem ausschnitt leuchten 30 smartphones.
noch ein blick auf die armhaltung, die das handy in der luft erzeugt. die arme nehmen mit der schulter ein gleichschenkliges dreieck ein, die spitze ist das handy. um das deutlich zu machen, nahm ich aus dem obigen konzertvideo einen ausschnitt und betonte die kanten:
ausschnitt aus dem szenario. links normal, rechts mit betonten kanten.
mit dieser interpretation sieht das publikum nach einem meer aus gleichschenkligen dreiecken aus:
das filmen mit dem smartphone bewirkt massenweise gleichschenklige dreiecke.
nur die beiden fallen aus dem rahmen (sie befinden sich im obigen bild ziemlich weit rechts):
symbolbild für die mischung aus chaos der umwelt und innerem verlangen nach ordnung. grafik: m.s.
meine redakteurin in wdr5/politikum tamara und ich überlegten am letzten freitag, was das dramolett, also das tagesaktuelle minihörspiel für den heutigen mittwoch sein könnte. wir müssen uns so früh absprechen, weil sich so ein stück nicht an einem tag herstellen lässt. die schritte sind:
themenfindung (freitag)
sprecher über die wdr sprecherdispo und den sehr kenntnisreichen jörg kernbach anfragen bzw. bestellen (freitag)
plot überlegen (wochenende)
manuskript schreiben und besprechen (montag)
die sprecher aufnehmen (dienstag)
produktion, also schnitt, musikkomposition, mischung (dienstag)
das stück war dienstag nachmittag fertig. ein sehr ernstes stück, das den autistic pride day am mittwoch zum anlass nimmt, aus dem innenleben einer autistin zu berichten, die den gebrauch des worts „autismus“ als worthülse zutiefst verurteilt. ausgangspunkt dafür war für mich ein blog der im letzten jahr verstorbenen kölner autistin sabine kiefner. vorn und hinten habe ich das motto ihres blogs zitiert:
Das größte Problem autistischer Menschen ist nicht der Autismus, sondern das Leben und Zurechtfinden in einer nichtautistischen Welt.
außerdem habe ich kernargumente aus ihrem offenen brief an stefan niggemeier paraphrasiert, wo sie dessen leichtfertige benutzung anprangert. der größte teil des texts ist rein fiktiv, von mir; es entsteht eine kleine medienkritik von faz über zeit bis bild. tanja haller spielt beide weiblichen rollen, martin groß spricht die zitate.
dramolett „worthülse autismus“ mit tanja haller und martin groß
einiges zur aufnahme- und mischtechnik. die schauspieler nahm ich in einem wdr-studio auf. der kollege am pult musste immer wieder die empfindlichkeit des mikrofons ändern, weil die stimmen meist sehr sehr leise sprechen, manchmal aber sehr laut sind. einige takes hat tanja vom mikrofon weg gesprochen; es klingt dann, als würden zwei personen miteinander sprechen, in verschiedenen räumen, obwohl es derselbe aufnahmeraum war. diese stellen sind am anfang und am schluss zu hören, wo die protagonistin zu tanja sagt, sprich langsam, und tanja sie beruhigt.
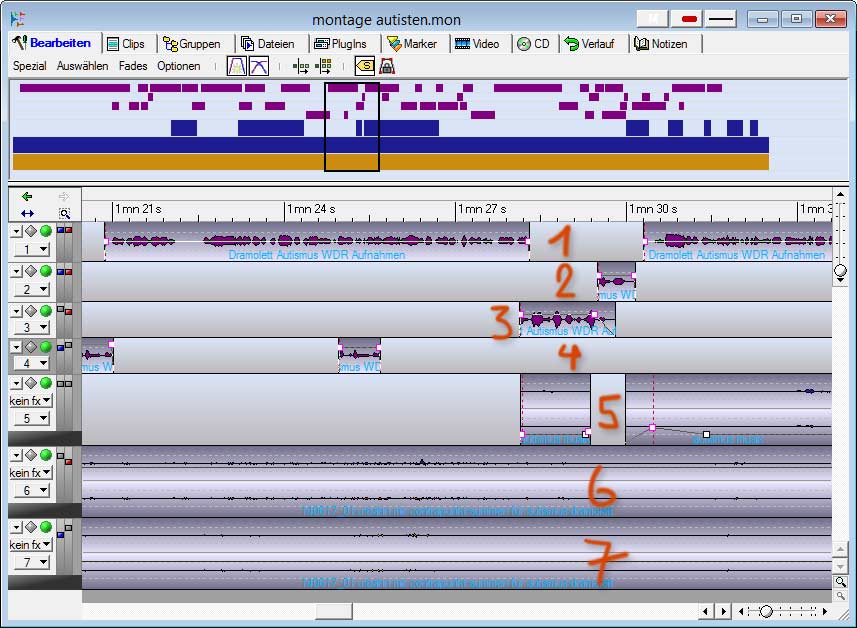
im screenshot unten ist das mischfenster zu sehen. die zahl der spuren – hier waren es sieben – schwankt je nach produktion. es können auch mal nur vier sein, in anderen fällen 15. ich finde, einer produktion sollte man die zahl spuren nicht anhören.
misch-fenster für die produktion des minihörspiels (bei klick wird es größer)
im oberen bereich sieht man die gesamte komposition. der große fensterinhalt darunter zeigt die einzelnen aufnahmeschnipsel mit ihren wellenformen. auf der ersten spur sitzt tanja, die nach innen gerichtete hauptstimme. sie ist die leitstimme, sie erzählt die geschichte; ich habe ihr deswegen eine minimale kompression gegeben, was man am „fx“ links in dieser spur sieht. auch die zweite spur hat einen fx, nämlich einen hall. es gibt in dem hörspiel einige stellen, wo martin „autisten“ ruft; diese befinden sich in dieser spur. spur 3 ist leicht links gepegelt; hier habe ich stimmen untergebracht, die ich räumlich trennen wollte. ebenso in spur 4, leicht rechts gepegelt. auf dieser spur befinden sich auch alle autistenfeindlichen pressezitate, gesprochen sehr nah am mikrofon von martin groß.
spur 5 ist eine von mir eigens dafür komponierte musik. ich habe dafür zunächst politikerreden genommen und auf ihre „ich“s reduziert. dann wählte ich zwei (digitale) musikinstrumente – kirchenorgel und jagdhorn – aus und begleitete die politiker (westerwelle, kohl, merkel, bush, rumsfeld, schavan etc.), wie sie „ich“, „mein“, „mir“ sagen, mit orgel und jagdhorn. diese musik entstand in einer so genannten sequencing software, also nicht in diesem programm. die spur ist sehr dominant, wenn man sie durch das hörspiel durchzieht. deswegen habe ich sie nur an bestimmten stellen eingesetzt, und ziemlich leise gepegelt. hier ein isolierter part daraus:
autismus-musik; ausschnitt
spur 6 besteht aus einer aufnahme in der u-bahn, direkt nach der schauspieleraufnahme, vom wdr in mein büro. mir ging im kopf herum, welche atmosphäre ich dem stück geben möchte, viele dinge wären möglich gewesen, und nahm einfach mal die atmo in der u-bahn auf, brummelte selbst dabei leise vor mich hin. hier ein ausschnitt:
summen in der u-bahn; ausschnitt
als ich diese atmo unter den text legte, funktionierte das in etwa. mir fehlte aber die wärme, die tiefe. statt die bässe in der aufnahme anzuheben, entschied ich mich für einen kunstgriff, den ich häufig anwende: ich kopierte die atmo auf die spur 7 und stimmte sie tiefer, in diesem fall um 24 halbtöne, also zwei oktaven. die beiden spuren, leicht rechts und links gepegelt, klingen zusammen fantastisch:
summen in der u-bahn; zweistimmig
das besonderen an diesen elementen auf den spuren 5, 6 und 7 ist, dass sie dem hörer kaum auffallen, weil er sich ja auf den text konzentriert, aber das ganze stück in eine stimmung hineinlenken, der er sich nicht entziehen kann. musik leistet das auch, aber meist platter.
von jungen kollegen werde ich oft gefragt, welche software ich für diese produktionen nutze. ich gebe dann meistens diese antwort: es gibt so viel gute schnitt- und mischsoftware, dass es nicht der rede wert ist, ein produkt beim namen zu nennen. dass ich mit einer älteren version von wavelab (und für die musikkomposition mit cubase) arbeite, ist wirklich nebensächlich; ich kenne dieses programme, denke mir manchmal, sie sind mir zu üppig, manchmal, sie sind mir nicht geradelinig genug, aber ich mag sie beide, und sie tun seit über 10 jahren ihren dienst.